The 38th Annual Conference on Neural Information Processing Systems had another successful year, with 16,500 participants—the highest in NeurIPS history—and 4,037 papers presented on the main track. While we enjoyed tutorials, workshops, and invited talks, our favorite part was the poster sessions, which gave us a chance to speak with authors, ask detailed questions, and delve deeply into the research. While the ACL 2024 conference we attended earlier in the year focused mostly on natural language processing (NLP), this conference covered a much broader spectrum, including topics such as large language models (LLMs), reinforcement learning, multimodality, deep learning architectures, and various research areas involving neural networks.
In this blog post, we highlight papers primarily related to Agentic AI—specifically those we believe will benefit Document AI. We also focus on the latest advances in OCR-free multi-modality. Before diving into the details of these papers, we’d like to provide a brief background on agents and explain why we—and the AI industry—are paying close attention to this area.
What is an AI Agent?
An AI agent is a software system that interacts with its environment, collects data, and autonomously performs tasks to achieve predefined goals. Leveraging technologies such as natural language processing (NLP), machine learning (ML), and large language models (LLMs), these agents operate with efficiency and adaptability, making decisions and taking actions without requiring constant human supervision.
At its core, an AI agent can observe, reason, and act—allowing it to navigate complex tasks dynamically. This capability is becoming increasingly relevant as AI-driven automation continues to advance across industries, from document processing and knowledge management to robotics and interactive assistants.
Summary of Agent and Document AI-related papers for documents from NeurIPS
Let's take a look at these great works. Each paper offers unique insights into the underlying theories and often includes practical implementations. If there’s a GitHub repo, give it a try for a hands-on understanding.
Chain of Agents: Large Language Models Collaborating on Long-Context Tasks source
This research introduces Chain-of-Agents (CoA), a novel framework designed to enhance LLM performance on long-context tasks. Unlike existing methods such as Retrieval-Augmented Generation (RAG) and context window extension, CoA takes a different approach by leveraging multiple LLM agents that collaboratively process text in segments.
How CoA Works
Multi-Agent Communication: Instead of overloading a single LLM with large amounts of tokens, CoA harnesses the natural communication capabilities of LLMs. The authors introduced two agents to accomplish long-context tasks. One is the worker agents that sequentially process and refine information, passing updated insights to the next agent—resulting in a more structured and efficient workflow for complex tasks. Once the worker agents complete their processing, the other agent, which is a manager agent, synthesizes their accumulated knowledge to generate the final response. This division of labor—where worker agents analyze segments of text while the manager agent produces the final output—ensures a more effective and scalable approach to long-context processing.
Google recently shared a blog post about the details of this framework, which illustrates the stage-by-stage process as well.
Zhang et al conducted extensive experiments across multiple datasets to demonstrate CoA’s superior performance in long-context tasks. Notably, it mitigates the "lost-in-the-middle" effect, a common challenge in long-context processing where essential information can get overlooked. The framework is not only highly effective but also interpretable and adaptable, making it a promising solution for improving LLM efficiency in real-world applications.
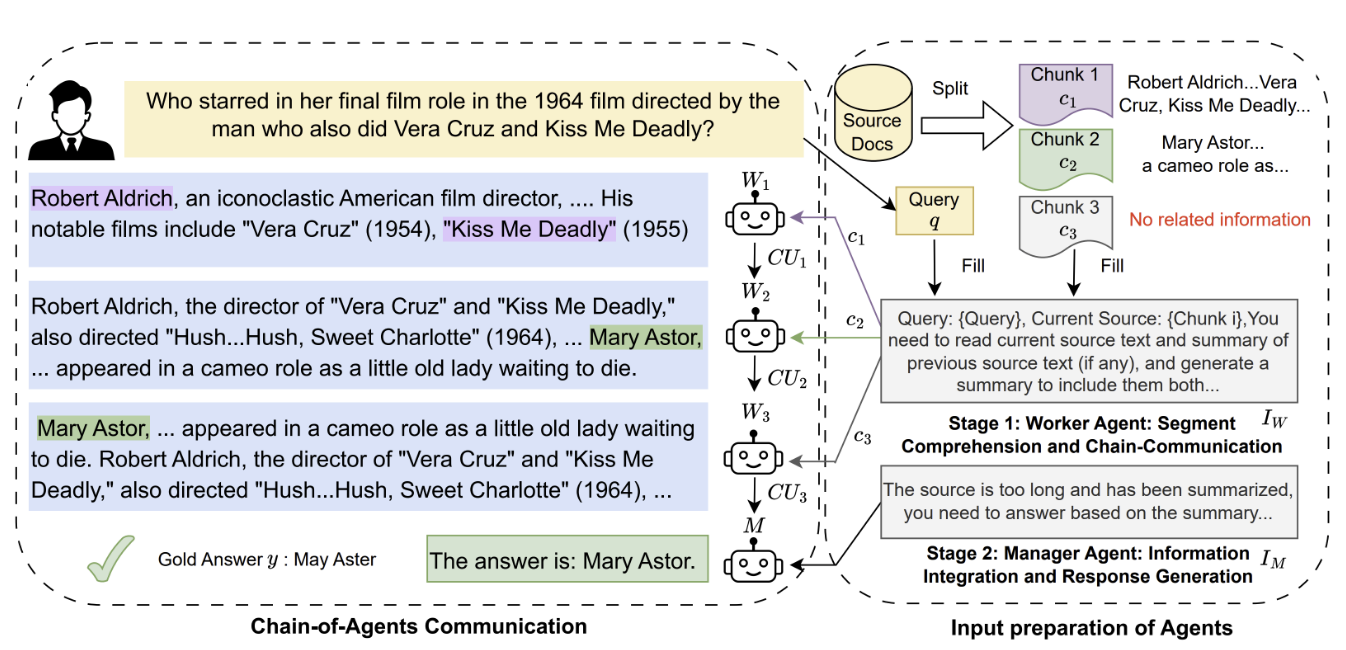
Figure 1 of the paper depicts the flow of the Chain-of-Agents framework. This framework consists of worker agents that sequentially answer the same question for different chunks of text, followed by a manager agent who synthesizes their contributions into a final answer.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows? Source GitHub
The Spider2-V benchmark evaluates multimodal agents' ability to automate data science and engineering workflows. It provides a realistic, executable computing environment with 20 enterprise-level applications, including complex graphic user interface (GUI) interactions and code generation tasks. The benchmark consists of 494 real-world tasks, revealing that even the most advanced models struggle with reliable automation. Researchers found that handling GUI actions, particularly in cloud environments, significantly affects performance, highlighting key areas for improvement in multimodal agent development. The dataset and code are publicly available.
Key Challenges faced by multimodal agents in the Spider2-V benchmark
- Limited automation of full data workflows
Even cutting-edge vision-language models (VLMs) like GPT-4V (gpt-4-1106-vision-preview) achieved only a 14.0% overall success rate, showing that current agents are far from fully automating data science and engineering tasks. The benchmark’s 494 tasks expose the difficulty models face in handling the complete complexity of these workflows.
- Difficulties with fine-grained GUI interactions
Multimodal agents struggled with tasks requiring precise interactions with GUIs. Even when given step-by-step instructions, their success rate for fine-grained GUI actions was just 16.2%. These agents often misidentify interactive elements, misclick buttons, and open incorrect windows, leading to failures. Accurate GUI interaction is critical for automating data workflows but remains a major weakness.
- Challenges in remote cloud-hosted environments
Tasks involving cloud-hosted workspaces had the lowest success rate at 10.6%. These scenarios added complexity, including network latency, unexpected pop-ups, and authentication requirements for services like BigQuery and Snowflake. These real-world challenges make automation even more difficult for multimodal agents.
Spider2-V highlights critical gaps in current AI capabilities, guiding future research to improve multimodal agent performance in real-world automation tasks.
On scalable oversight with weak LLMs judging strong LLMs source
This research paper investigates the effectiveness of using LLMs as judges to supervise stronger LLMs across various tasks, exploring debate and consultancy protocols as scalable oversight methods. The study benchmarked these protocols against direct question-answering, examined performance across different task types, and capability gaps between the judge and agent LLMs. Results indicate that debate generally outperforms consultancy, although its advantage over direct questioning depends on the task. The paper also explores open-role variations where agents choose their own arguments, revealing that debate is less likely to amplify incorrect answers. Finally, the findings suggest that while stronger models generally make better judges—especially in debate protocols—very weak judges may not benefit from debate, and having a judge that is equal in strength to the debaters might not be ideal.

Figure 4 of the paper. For extraction tasks involving judges, stronger debaters tend to lead to higher judge accuracy. However, in closed extraction tasks—where the judge has access to all the same information as the debaters—there isn't a clear trend
Multi-LLM Debate: Framework, Principals, and Interventions source
The authors of this paper propose a theoretical framework for multi-LLM debate, framing it as a form of in-context learning. They highlighted key challenges, such as the "echo chamber" effect and shared misconceptions, which can hinder effective debate. To address these issues, they introduced three interventions—diversity pruning, quality pruning, and misconception refutation—aimed at improving debate efficacy. The paper presents theoretical justifications for these interventions, along with empirical results from experiments on four benchmark datasets, demonstrating consistent performance improvements across various LLMs.
- Diversity pruning maximizes information entropy in model responses by selecting a subset of responses that differ the most from one another. This helps reduce the echo chamber effect by ensuring a broader range of perspectives.
- Quality pruning enhances response relevance by selecting those most aligned with the task. This increases the likelihood that the debate converges on correct answers.
- Misconception refutation identifies and corrects errors in model responses by first prompting for a list of misconceptions, then requesting a refutation and a revised, more accurate response.
These interventions collectively help improve the robustness of multi-LLM debate, mitigating biases and increasing the reliability of AI-driven decision-making.
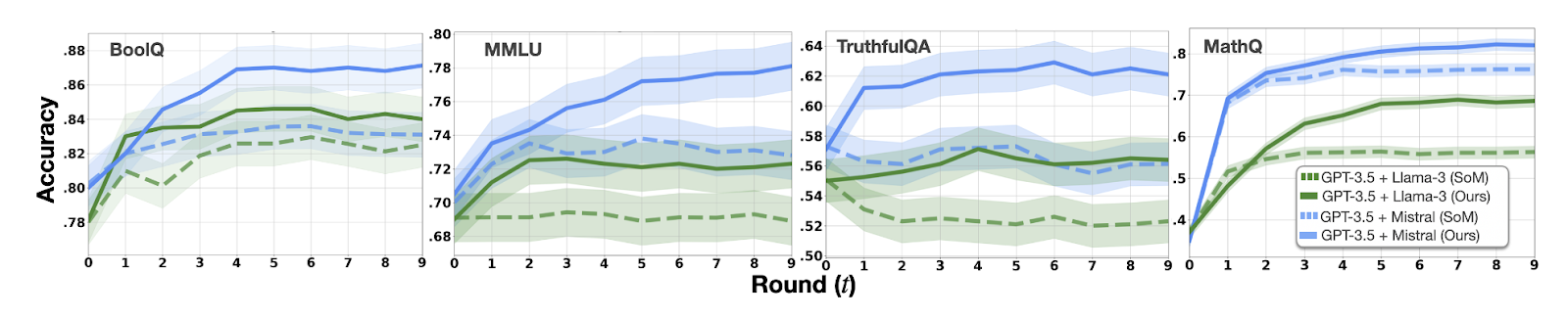
Figure 3 of the paper. The comparison in accuracy per round between the previous debating framework Society of Minds SoM and this paper (ours) when combining GPT3.5 with Llama-3 or Mistral. Please refer to Table 1 of the paper to see in detail how using one or two model types as debaters have performed in different settings.
LLM Evaluators Recognize and Favor Their Own Generations Source
This research explores the phenomenon of self-preference bias in LLMs, where models tend to rate their own outputs more favorably than those of similar quality. The study investigates whether this bias originates from the models' ability to recognize their own outputs—a process referred to as self-recognition. Through a series of experiments, the authors observed a linear correlation between self-recognition capability and the strength of self-preference bias. In other words, as an LLM's ability to identify its own outputs increases, so does its tendency to favor them.
Further experiments involving fine-tuning demonstrated that manipulating self-recognition levels led to proportional changes in self-preference bias. Notably, when LLMs were fine-tuned to either enhance or diminish their self-recognition on one dataset, these adjustments transferred to another dataset, reinforcing the consistency of the correlation. At the individual example level, a positive correlation was observed: whenever an LLM correctly recognized a summary from a pair, it was more likely to prefer that same summary.
While these findings suggest a potential causal link between self-recognition and self-preference, the study acknowledges that the observed correlation does not, by itself, prove causality. The paper emphasizes the importance of addressing self-recognition bias to ensure unbiased LLM evaluations and enhance overall AI safety while also calling for further research to conclusively validate the causal relationship between self-recognition and self-preference bias.
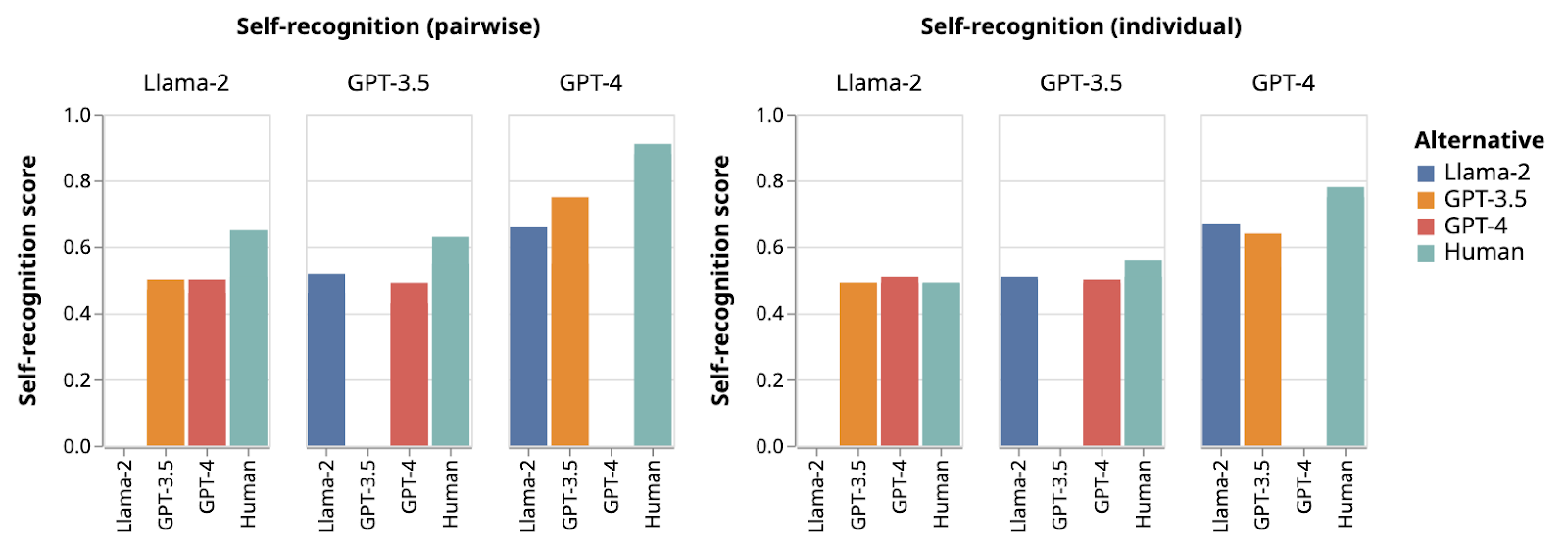
Self-recognition without any fine-tuning, the image on the left shows pairwise results between the sources, while the one on the right shows individual measurements.
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering Paper Github
This research introduces SWE-agent, a system designed to boost the performance of LLMs in software engineering tasks by creating a specialized agent-computer interface (ACI). This ACI serves as an abstraction layer between the LLM and the computer, offering a simpler and more efficient interaction than existing interfaces. It incorporates features like concise feedback, guardrails against errors, and efficient search and editing commands, which together enhance the agent’s ability to create and edit code files, navigate entire repositories, and execute tests or other programs.
Experiments using GPT-4 Turbo and Claude 3 Opus demonstrate that SWE-agent significantly outperforms previous methods on software engineering benchmarks, highlighting the importance of interface design tailored to the specific capabilities and limitations of LLMs. Just as humans benefit from well-designed software applications, LLM agents also thrive with specialized interfaces. The ACI in SWE agent includes modules for search/navigation, file viewing, file editing, and context management. It utilizes special commands like find_file, search_file, and search_dir for searching and a file viewer with commands such as scroll_down, scroll_up, and goto for navigation. The edit command enables agents to replace specific ranges of lines, while a code linter helps prevent errors during editing.
Overall, the research underscores that interface design plays a crucial role in the performance of LLM agents. By leveraging a tailored ACI, SWE agent not only improves task efficiency but also solves significantly more instances on the SWE-bench benchmark compared to a baseline agent using only the default Linux shell.
.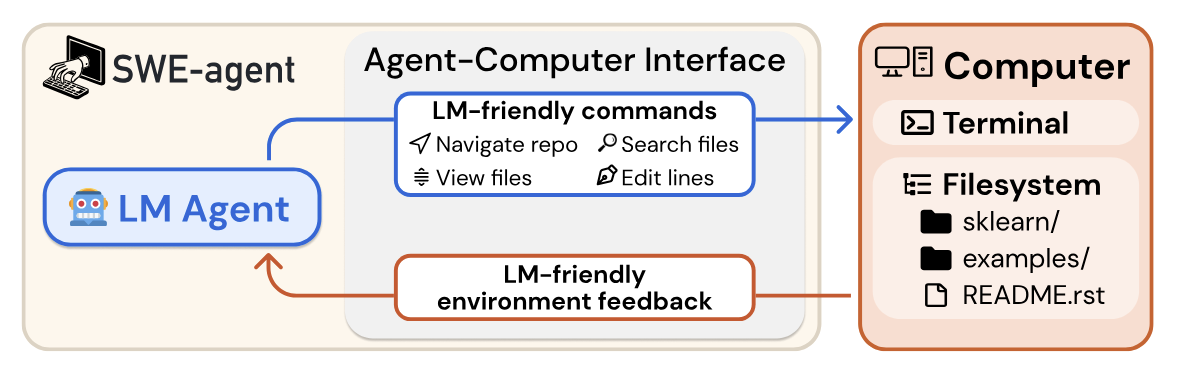
Figure 1 of the paper, SWE-agent interacts with a computer through an agent-computer interface (ACI), which includes the commands the agent uses and the format of the feedback from the computer.
Hierarchical Visual Feature Aggregation for OCR-Free Document Understanding source
Although this research isn't entirely in line with our current Agent theme, we want to highlight a document understanding paper that outperforms Dessurt, Donut, and Pix2Struct—some of the most powerful OCR-free multimodal LLMs in the field. This paper introduces the Hierarchical Visual Feature Aggregation (HVFA) module, which reduces the number of input tokens to LLMs by leveraging multi-scale visual features to handle various document images and font sizes. The approach effectively tackles challenges posed by complex graphical elements, such as charts, diagrams, and non-standard layouts, which typically strain models due to limited receptive fields. Additionally, the study points out that models like Dessurt, Donut, and Pix2Struct incur high computational costs because they require pretraining from scratch before task-specific fine-tuning.
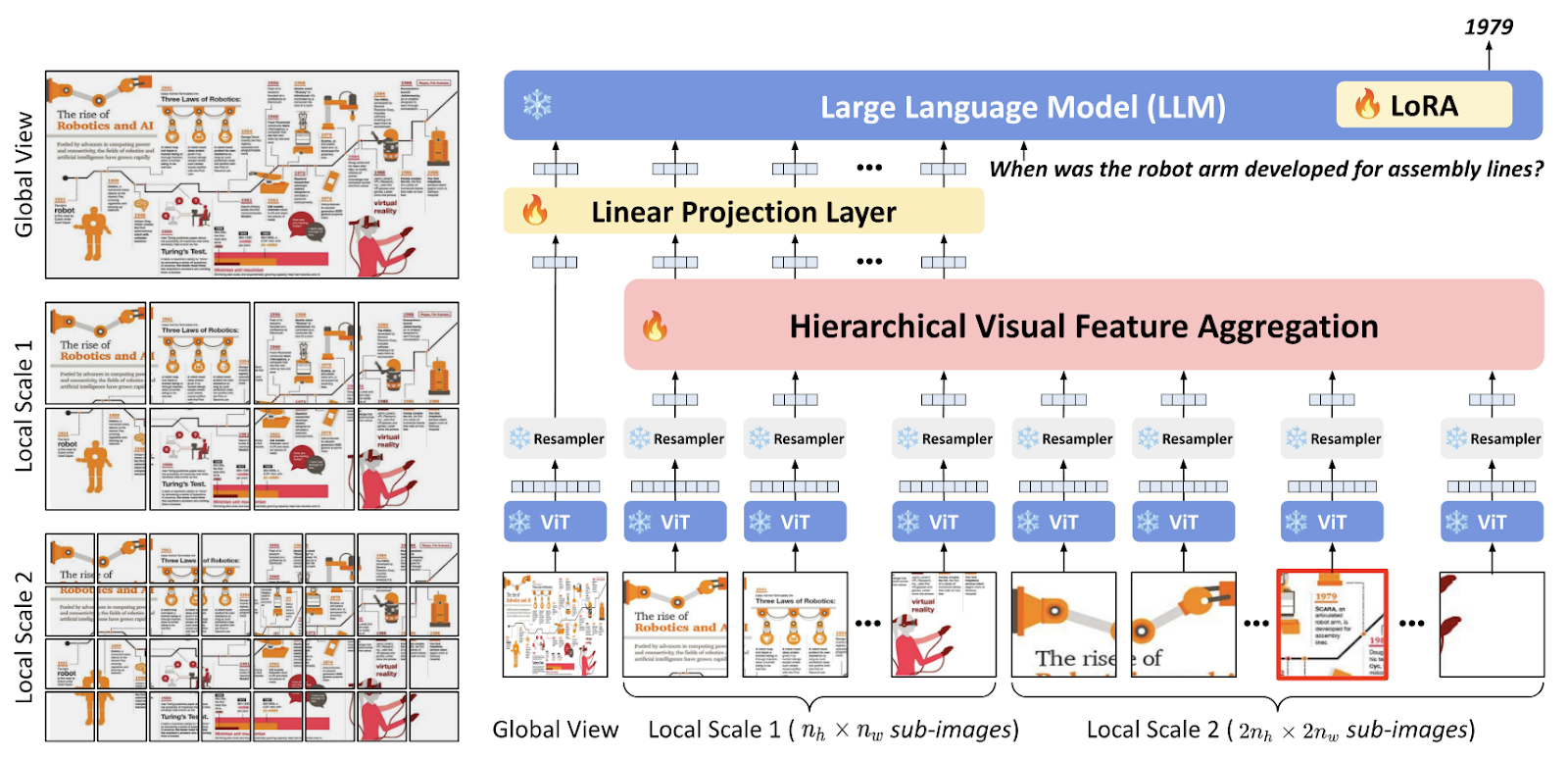
Figure 1 of the paper; The proposed framework features a Hierarchical Visual Feature Aggregation (HVFA) module that aggregates visual features extracted at multiple scales. These aggregated features are then fed into an LLM, which generates a language response in an autoregressive manner. Notably, the sub-image highlighted by the red box contains text that is crucial for answering the input question, emphasizing the model's need to accurately recognize visually detailed elements from high-resolution images
Conclusion
Thank you for reading this deep dive into some of our favorite papers from NeurIPS. Our focus at Pythonic Corporation is on automating document understanding tasks for the escrow and title industry, and we remain committed to delivering the latest and best AI solutions in the field to our customers. As always, we encourage you to study the original works and explore the code and datasets where available. The innovations presented at NeurIPS 2024 continue to inspire and inform the future of AI, and we look forward to seeing how these ideas evolve and impact real-world applications.
Editor Note: Pythonic employs a team of experts in engineering, AI, and machine learning. With their insights and expertise, Pythonic solutions simplify the complicated, applying cutting-edge AI to the title industry. This latest post highlights their knowledge and ongoing learning for the company and its clients.
