With innovation at a seemingly unprecedented pace, staying updated with the state of the art is crucial for every AI and machine learning practitioner. Participating in conferences like ACL is a significant way to keep up with the latest developments, learn from the best, and stay at the forefront of innovation. It is invaluable for us at Pythonic to familiarize ourselves with emerging research and understand the trends shaping the future of AI for the title and escrow industry.
About Association for Computational Linguistics (ACL)
According to Google Scholar metrics, ACL is the top-ranked conference in the computational linguistics category, with the highest H5-index and H5-median at the time of this blog post's publication. This year, 940 primary conference papers and 975 findings, along with other workshop papers, were presented.
In recent years, the community has focused on machine learning techniques, information extraction, machine translation, and natural language processing (NLP) applications. However, this year's topics were notably diverse. The greatest attention was given to NLP applications, followed by resources and evaluation and efficient/low-resource methods for NLP.
Special Theme of ACL 2024
This year's conference highlighted an important theme: open science, open data, and open models for reproducible research. The goal was to reflect on and stimulate discussion about increasing transparency in the field, promoting open models, and supporting open-source initiatives as an alternative to closed approaches in NLP. Topics focused on high-quality datasets, innovative evaluation methods, implementation tools, and models thoroughly documented and accompanied by model cards. Amazing papers on open data and models were presented, but this post will mainly focus on document AI-related research.
Document AI Background
Document AI leverages artificial intelligence to comprehend, analyze, and process documents that mimic human understanding. It covers a wide range of tasks, from extracting specific information to classifying documents and even understanding the relationships between different elements within a document. The main goal of document AI is to automate the reading and comprehension of documents, making processes like data entry, information extraction, document classification, and improved quality control more efficient and accurate.
Document AI tasks can include:
- Document Classification: Categorizing documents into predefined classes, like invoices, lender-related documents, or tax forms.
- Entity Recognition: Finding and labeling specific entities within the text, such as people, organizations, or locations.
- Layout Analysis: Understanding the structure of a document, such as headers, footers, tables, and signatures.
- Relation Extraction: Identifying and understanding relationships between entities within a document, for example, linking a signature to the name of a buyer or seller.
At Pythonic, document AI is essential for accurately understanding document layouts, identifying their types, and extracting key information. This capability is crucial for our Document Package Automation product, which relies on reading and interpreting documents with precision. By identifying specific components, such as names, dates, and signatures, and applying customer-specific business logic, our system organizes document pages from a large document package dump into smaller, cohesive, and relevant documents, ensuring tailored and consistent packaging based on client needs.
Summary of Interesting Papers from ACL 2024
Towards a New Research Agenda for Multimodal Enterprise Document Understanding (source)
This paper explores the key limitations of current multimodal document understanding models, particularly when applied in enterprise settings, where complex, unstructured data and diverse document types present substantial challenges to accurate and efficient document processing. Despite achieving impressive results on certain benchmarks, these models face significant challenges in dataset curation, model development, and real-world evaluation. The authors identify critical gaps limiting their adoption in practical enterprise applications.
Key limitations identified include:
- Data: Limited publishers, under-represented associative tasks, and insufficient grounding are some of the major challenges in dataset quality and diversity.
- Model: Issues such as calibration, licensing, and grounding are highlighted as significant barriers to model robustness and usability in practical settings.
- Evaluation: The evaluation approach also faces limitations, particularly regarding field-level performance and understanding reading order, which are crucial for accurately interpreting document layouts.
The paper proposes a new research agenda to address these challenges, focusing on practical enterprise applications, calibration, and contextual evaluation metrics, ultimately driving the field toward higher impact in real-world settings.
One of the key challenges highlighted in this paper aligns with the challenges we are currently addressing in our Quality Control product: establishing the relationship between the authorized signers, their signatures, and their titles to ensure the integrity of signed packages. While this task may seem straightforward for humans, it is highly challenging for AI to determine these relationships accurately. These complexities underscore the difficulty of implementing AI for accurate, reliable, and auditable enterprise workflows.
Hypergraph-Based Understanding for Document Semantic Entity Recognition (source)
This paper introduces Hypergraph Attention (HGA), a novel method for document semantic entity recognition (SER). The main goal of SER is to identify and classify text segments within documents that convey specific semantic meanings, extending beyond the traditional identification of entities like Person, Organization, and Location. HGA utilizes hypergraphs to extract semantic entities from text nodes by creating hyperedges between feature nodes. The authors improve entity extraction performance by incorporating span position encoding and a balanced hyperedge loss function. They evaluate their approach by implementing HGALayoutLM, a new SER model based on GraphLayoutLM, and conduct extensive experiments on multiple datasets. The results demonstrate that HGA is particularly effective for SER tasks in documents with fewer label categories.
LMDX: Language Model-based Document Information Extraction and Localization (Source)
This paper introduces a new methodology called LMDX (Language Model-based Document Information Extraction and Localization) for extracting information from visually rich documents (VRDs) using large language models (LLMs). The main idea is to leverage LLMs' ability to understand and process text and enhance their VRDs performance by incorporating layout information. It utilizes layout information, where spatial positions of text segments are encoded as coordinate tokens and included in the LLM prompts. This approach allows for the effective reuse of existing LLMs for document understanding tasks without needing changes to their architecture.
The process operates in four stages: chunking documents into smaller sections, generating prompts with layout data and extraction targets, running the LLM to extract information, and decoding the results to precisely locate entities within the document.
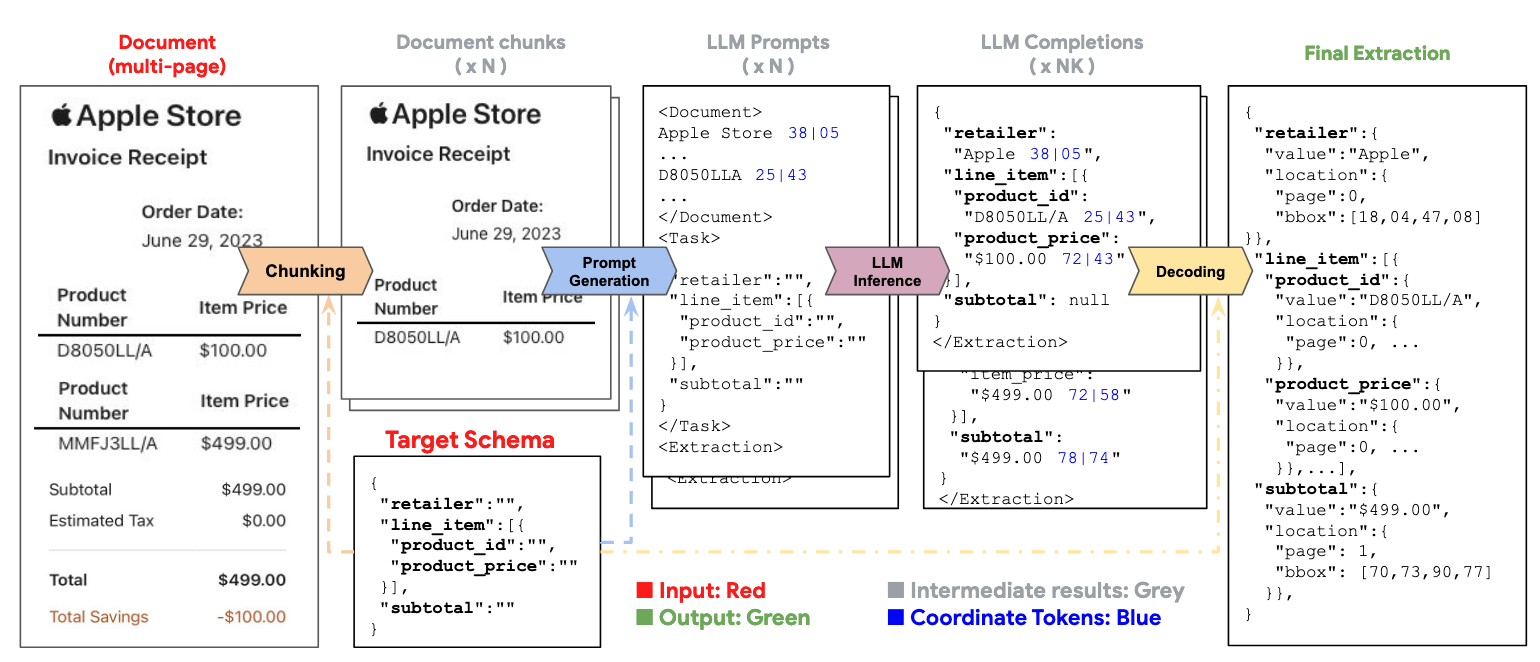
Image: LMDX organizes information extraction for LLMs into four stages. It generates prompts with text and layout to enable precise extraction. The LLM’s JSON outputs support hierarchical extraction and use segment identifiers for accurate localization, minimizing hallucinations.
Let’s look closer at the second stage, which involves creating an LLM prompt. Each prompt contains the document representation, task description, and target schema using XML-like tags (to see a detailed example of this XML-like tags, refer to Figure 10 of this paper). The document representation includes the segment text and its corresponding normalized coordinates, encoded as tokens. After testing various schemes, the authors mentioned that the optimal approach used line-level segments with two coordinates ([xcenter, ycenter]), ensuring an efficient prompt token length.
The methodology is data-efficient, performing well with minimal training data, and has demonstrated effectiveness across various LLMs like PaLM 2-S and Gemini Pro.
DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding (Source)
This research paper introduces DocLLM, a language model designed to enhance document understanding by incorporating spatial layout information. DocLLM leverages bounding box coordinates from Optical Character Recognition (OCR) to capture the spatial arrangement of text within documents. This allows the model to reason about the structure of documents beyond just the textual content. The paper highlights two key innovations: disentangled spatial attention, which allows the model to selectively focus on text or layout information, and a block infilling pre-training objective, which helps the model learn to predict missing text segments in documents. These features allow DocLLM to address the challenges of irregular layouts and heterogeneous content found in many enterprise documents. The authors (Wang et al.) demonstrate the effectiveness of DocLLM, and their results show that DocLLM significantly outperforms other models on most datasets, especially those involving complex document layouts.
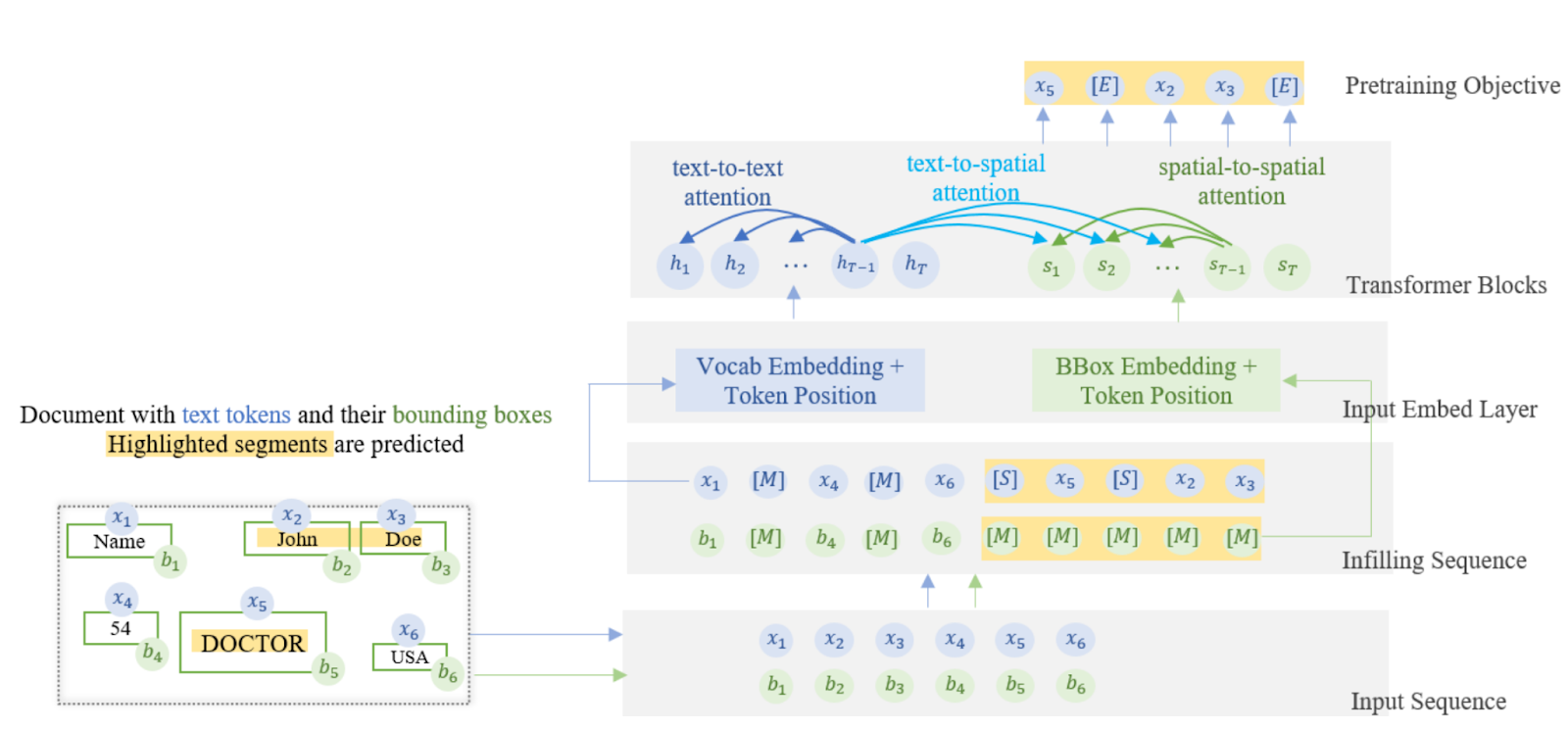
Image: DocLLM architecture with disentangled spatial attention and infilling objective: text tokens and bounding boxes are processed, with masked segments predicted autoregressive. Spatial attention connects text and layout for improved understanding. (Figure 2 of this paper)
3MVRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding (Source)
This research paper proposes a novel method for understanding visually rich form documents, like receipts and forms, using a multi-modal, multi-task, multi-teacher knowledge distillation model called 3MVRD. The model aims to overcome the challenges of understanding forms involving two distinct authors (designers and users) and incorporating diverse visual cues. 3MVRD leverages knowledge from fine-grained and coarse-grained levels, enabling the model to capture detailed token-level information and high-level entity-level structures. The paper outlines various losses implemented to facilitate this knowledge transfer from multiple teachers. The model is evaluated on two publicly available datasets, FUNSD and FormNLU, and the results demonstrate its superior performance compared to existing baselines.
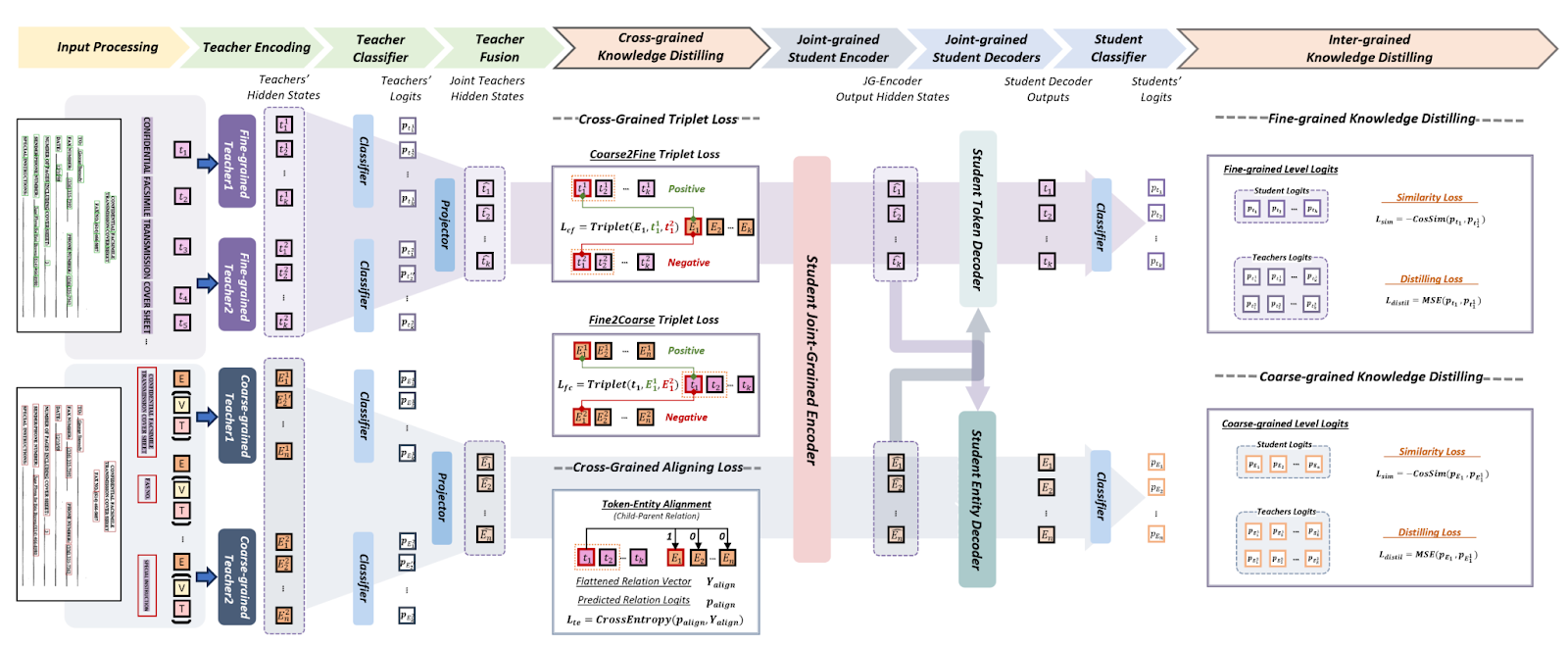
Image: A detailed structure of the 3MVRD framework is depicted here. (Figure 1 of this paper)
TTM-RE: Memory-Augmented Document-Level Relation Extraction (Source)
In this paper, the authors (Gao et al.) introduce TTM-RE, a novel approach for tackling document-level relation extraction (DocRE). DocRE is a challenging Natural Language Processing (NLP) task that involves identifying and classifying the relationships between entities within a document, even when these entities appear in different sentences. Unlike sentence-level relation extraction, DocRE requires understanding context across multiple sentences or paragraphs, making it a complex problem.
TTM-RE addresses this challenge by leveraging a memory-augmented architecture called the Token Turing Machine (TTM). This memory module allows the model to "read" and "write" information during processing, enabling it to retain and retrieve relevant details about entities (referred to as head and tail entities) across long sequences. This is particularly valuable for tracking relationships that span several sentences.
The paper includes extensive experiments and ablation studies, which show how different memory configurations (such as varying memory sizes and layers) impact performance. These studies highlight that TTM-RE is particularly effective at improving relation extraction in scenarios with infrequent relation classes, where other models typically struggle.
The authors (Gao et al.) compare TTM-RE against various baseline models and test it in challenging settings, including rare relation classifications and highly unlabeled data environments. The results demonstrate that memory-augmented models, like TTM-RE, offer significant potential for improving document-level relation extraction, especially in real-world scenarios where data can be noisy or incomplete.
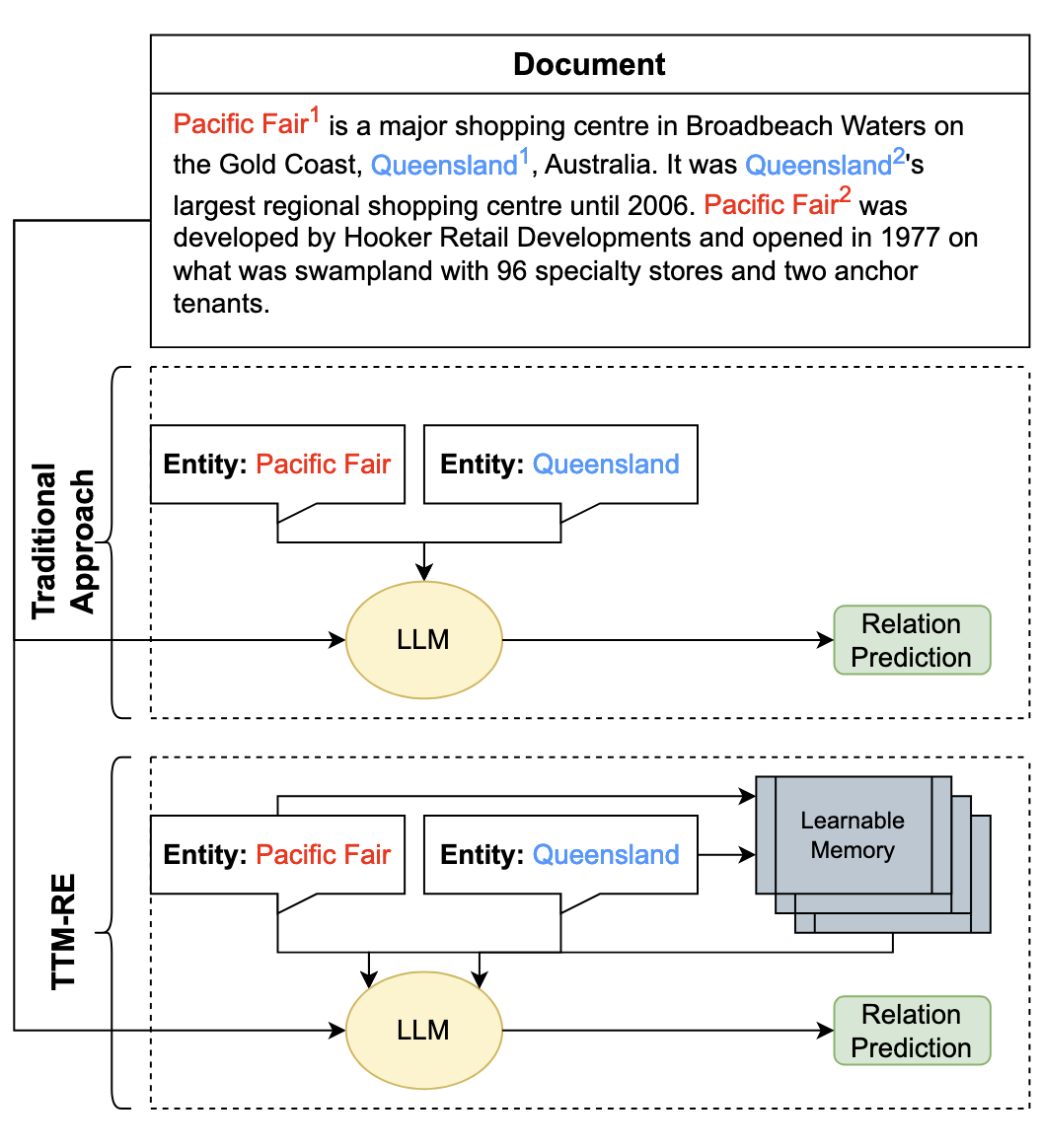
Image: This picture depicts how TTM-RE is different from traditional approaches. (Figure 1 of this paper)
Automatic Layout Planning for Visually-Rich Documents with Instruction-Following Models (source)
Finally, we’d like to highlight an interesting research paper from Adobe that addresses the challenges non-professional users face in graphic design. Many individuals struggle to create visually appealing layouts due to limited design skills and resources. As high-tech products become more widely used, it's increasingly important to make these tools accessible to everyone.
The authors (Zhu et al.) propose a novel approach to automate the layout planning of visually rich documents through instruction-following models. They recognize the limitations of current design tools and the difficulties non-professional users experience when trying to produce professional-looking designs. To tackle this, they introduce DocLap, a multimodal framework that simplifies the design process by allowing users to specify design goals and component arrangements through instructions.
DocLap is trained using three layout reasoning tasks: Coordinates Predicting, Layout Recovering, and Layout Planning. The three tasks enable the model to understand and execute layout instructions effectively. Experimental results on two benchmark datasets, Crello and PosterLayout, show that DocLap outperforms few-shot GPT-4V models, demonstrating the potential of instruction-following models to streamline design and offer a more user-friendly experience.
Discussion
Thank you for reading the research papers we’ve found very interesting. These papers reflect some of the latest AI, ML, and NLP developments. We encourage you to dive deeper into the papers that resonate with you as they showcase innovative approaches and ideas that may shape the future of our industry.
At Pythonic, we begin with a foundation of in-depth research, ensuring that our solutions are firmly rooted in real-world use cases that directly benefit the escrow and title industry. Our process starts with thoroughly understanding the latest advancements and evolves to what AI advancements can address the specific pain points that title and escrow officers face day in and day out. Once a potential solution is validated, we transition into product development, continuously refining and improving our offerings to meet the ever-changing demands of the industry.
We are focused on staying ahead of the curve by actively integrating the latest innovations in document understanding and learning from leading conferences like ACL 2024 and other cutting-edge research forums. While working closely with key players in the title insurance space to understand today’s challenges, we remain committed to pushing boundaries, ensuring that our clients always receive state-of-the-art, highly accurate, and reliable results.
Editor Note: Pythonic employs a team of experts in engineering, AI, and machine learning. With their insights and expertise, Pythonic solutions simplify the complicated, applying cutting-edge AI to the title industry. This latest post highlights their knowledge and ongoing learning for the company and its clients.
