Editor Note: Pythonic employs a team of experts in engineering, AI, and machine learning. With their insights and expertise, Pythonic solutions simplify the complicated, applying cutting-edge AI to the title industry. This latest post highlights their knowledge and ongoing learning for the company and its clients.
In this blog post, we explore the exciting topic of Retrieval-Augmented Generation (RAG), a technology that is becoming essential in the field of Generative AI. RAG combines traditional Natural Language Processing (NLP) techniques with retrieval functions to enhance the AI model’s response generation capabilities. This approach allows AI models to dynamically pull information from external databases or documents, integrating this data into the generation process to produce responses that are not only relevant but also contextually rich.
The technology behind RAG has rapidly advanced in recent years, attracting a lot of interest in recent months. Initially, while early versions of RAG showed potential, they struggled with more complex requests. Today, we're seeing more refined versions of RAG being used in a wide array of AI applications. At Pythonic, we've witnessed how RAG has enhanced our products, enabling our systems to tap into a wealth of information, similar to how people use various sources to ensure their answers are well-informed and accurate.
At Pythonic, we specialize in document AI in the real estate industry. RAG is one component in our ensemble approach to the precision-first understanding of real estate documents. For example, a critical step in a title examination is verifying the chain of titles. The necessary documents for the COT are various types of deeds that are buried in a large collection of documents. RAG retrieves the correct documents and even the right pages, allowing LLMs to verify details such as grantors and grantees.
Basic and Advanced RAG pipelines
A Basic or Naive RAG pipeline consists of three fundamental processes each designed to enhance the capabilities of large language models (LLMs) including indexing, retrieval and generation. Let’s take a closer look at each of these steps:
Indexing: The fundamental difference between well-established keyword-driven retrieval and semantic search is the advanced LLMs for semantic embeddings, which has also been the engine to the recent generative AI explosion.
In this step, documents are organized into chunks and processed through the LLMs to create numerical vectors (a.k.a. embeddings) that capture their semantic meanings. Embeddings are dense numerical representations of text, which makes it easier and more powerful to compare if two chunks are relevant to each other or not. Queries are converted into vectors using the same LLMs. This allows for more accurate and meaningful searches by matching the semantic content rather than just keywords.
Retrieval: This step involves retrieving the most relevant text chunks and therefore documents where the chunks are within based on a specific query or question. Given all the documents and query embeddings from the previous step, they get stored in a vector store (database). Documents in close distances to the query in the embedding space are considered to be similar, then with help of the vector store can pick top-K documents close to the question. The key elements in this step are efficiency, accuracy, and scalability. The accuracy of such document retrieval is significantly dependent on the quality of the NLP embedding model.
To meet the demands in the real world, due to the high volume of documents that need to be indexed, the embedding solution should be scalable and capable of creating a vector database in a timely manner. Meanwhile, there are stiff requirements to host the generated vector database so that similarity computing can be performed in RAM, otherwise, the resultant disk I/O would dramatically slow down the process and therefore hurt its usability.

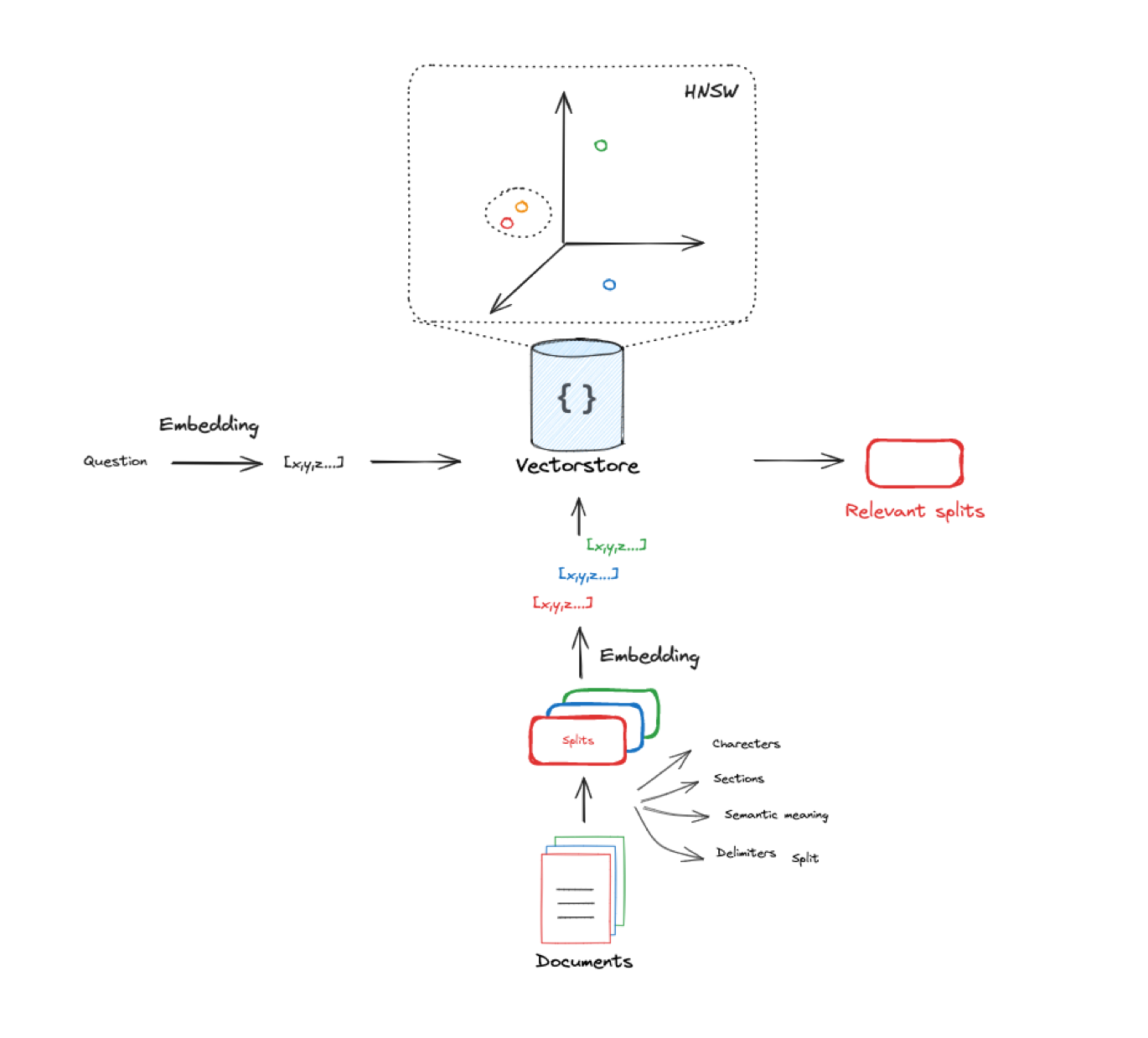
image caption: This image depicts the Indexing and Retrieval steps of a naive RAG pipeline. Documents are split into chunks or splits. Using an LLM, their numerical representations or embeddings are stored in a vector space to retrieve the most relevant content to the given question. The result of this step is a set of relevant splits. [Image source by LangChain]
Generation: Given the precisely retrieved and well-defined context (chunks from retrieval), the LLM now generates a response. The prompt clarifies the context of the query, grounds the generative response to the given facts, outlines the expected characteristics of the response, and finally sets the stage for more targeted and accurate outputs. Leveraging the rich, relevant context in this last step greatly enhances the output’s robustness and reliability.
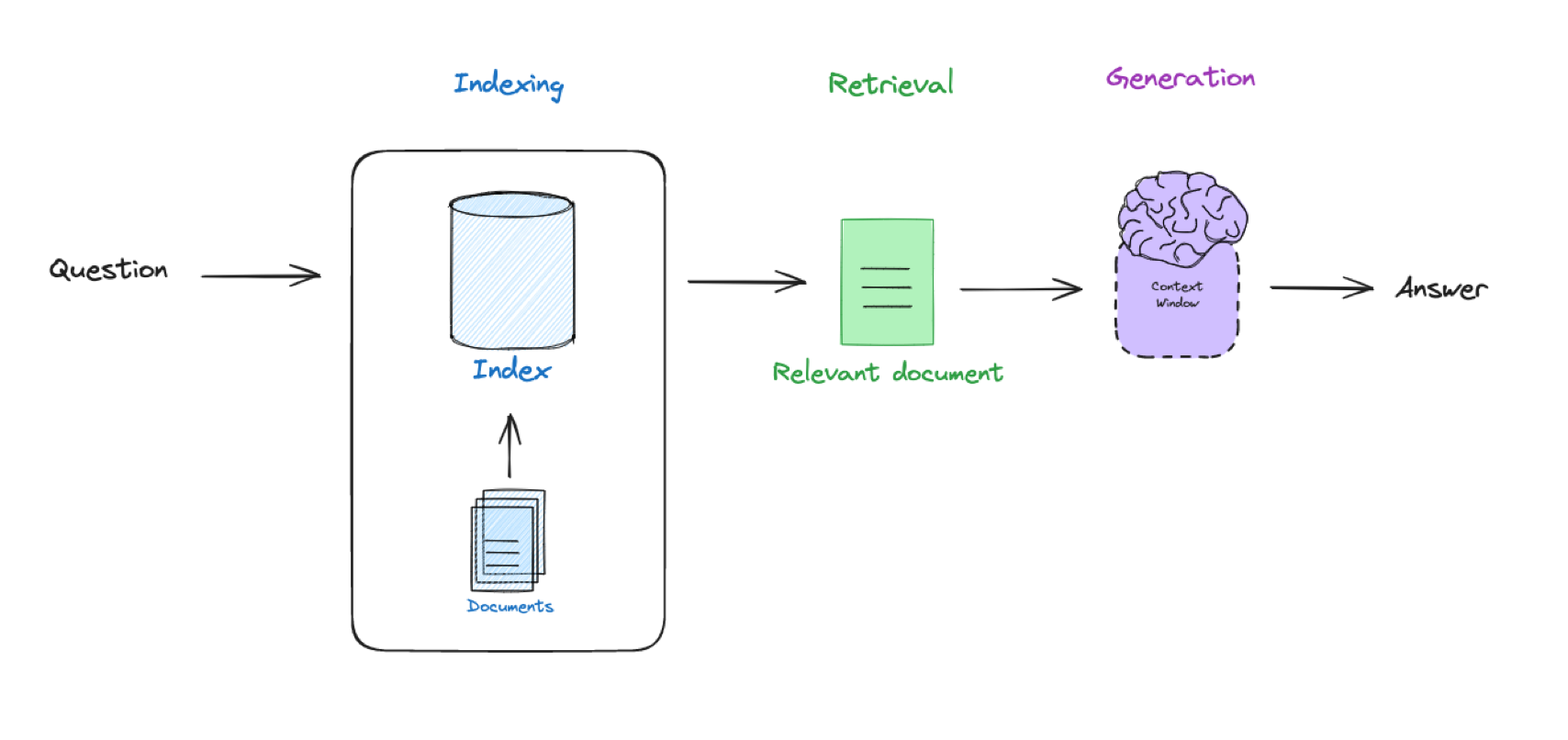
The basic RAG pipeline is depicted in the following image.

Image caption: The basic RAG pipeline consists of three parts: Indexing, Retrieval, and Generation. During Indexing, we load a set of documents, split them into smaller chunks, and generate embeddings for each chunk. In the Retrieval step, chunks and their embeddings are stored in a vector database, and we use a user query to identify the top K most relevant chunks.
Finally, in the Generation phase, we combine these relevant chunks with the user query to create the prompt for the LLM. [Image source by LangChain]
Although a basic RAG pipeline can enhance results, it's important to note the value of more advanced techniques.

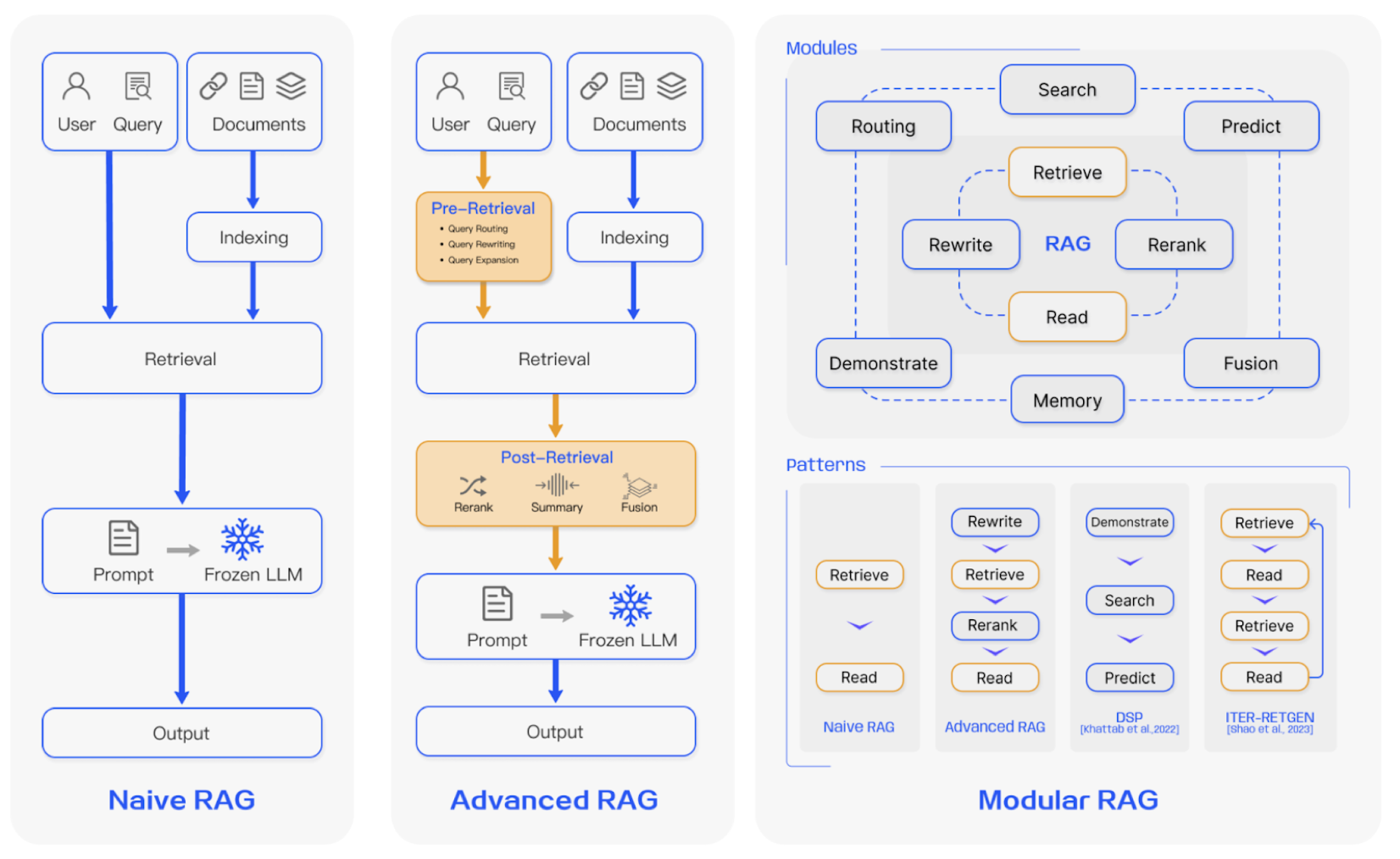
Image caption: Gao et al. conducted a comprehensive review, highlighting three main RAG approaches: Naive (basic) RAG, Advanced RAG, and Modular RAG. Naive RAG includes Indexing, retrieval, generation. Advanced RAG builds on this by incorporating optimization strategies for pre-retrieval and post-retrieval. Modular RAG, on the other hand, introduces a more flexible approach, such as fine-tuning the retriever for enhanced adaptability. [image source]
Here are examples of the Advanced and Modular RAG approaches: The first two are from the Advanced RAG techniques, and the last two belong to Modular RAG.
- Sentence-window retrieval: This method operates on a granular level, focusing on individual sentences. After retrieval, the original sentence is replaced with a larger window of surrounding sentences to provide more context to the LLM during prompting.
- Auto merging retrieval (Hierarchical Retriever): In this approach, a hierarchy is constructed where larger parent nodes contain smaller child chunks. If a parent node encompasses the majority of its retrieved children, it replaces them, streamlining the retrieval process.
- RAG-Fusion: This Modular RAG component uses a multi-query strategy to broaden user queries into diverse perspectives. It employs parallel vector searches and intelligent re-ranking to reveal both explicit and transformative knowledge.
- Memory Module: This module enhances retrieval by leveraging the LLM’s memory, creating an extensive memory pool that aligns text more closely with data distribution through iterative self-enhancement.
Evaluation:
Although reviewing a handful of results can be helpful, it's not fully reassuring without evaluating the specific downstream tasks relevant to your needs. Starting with benchmarks and datasets is an excellent approach, especially if you lack an in-house dataset.
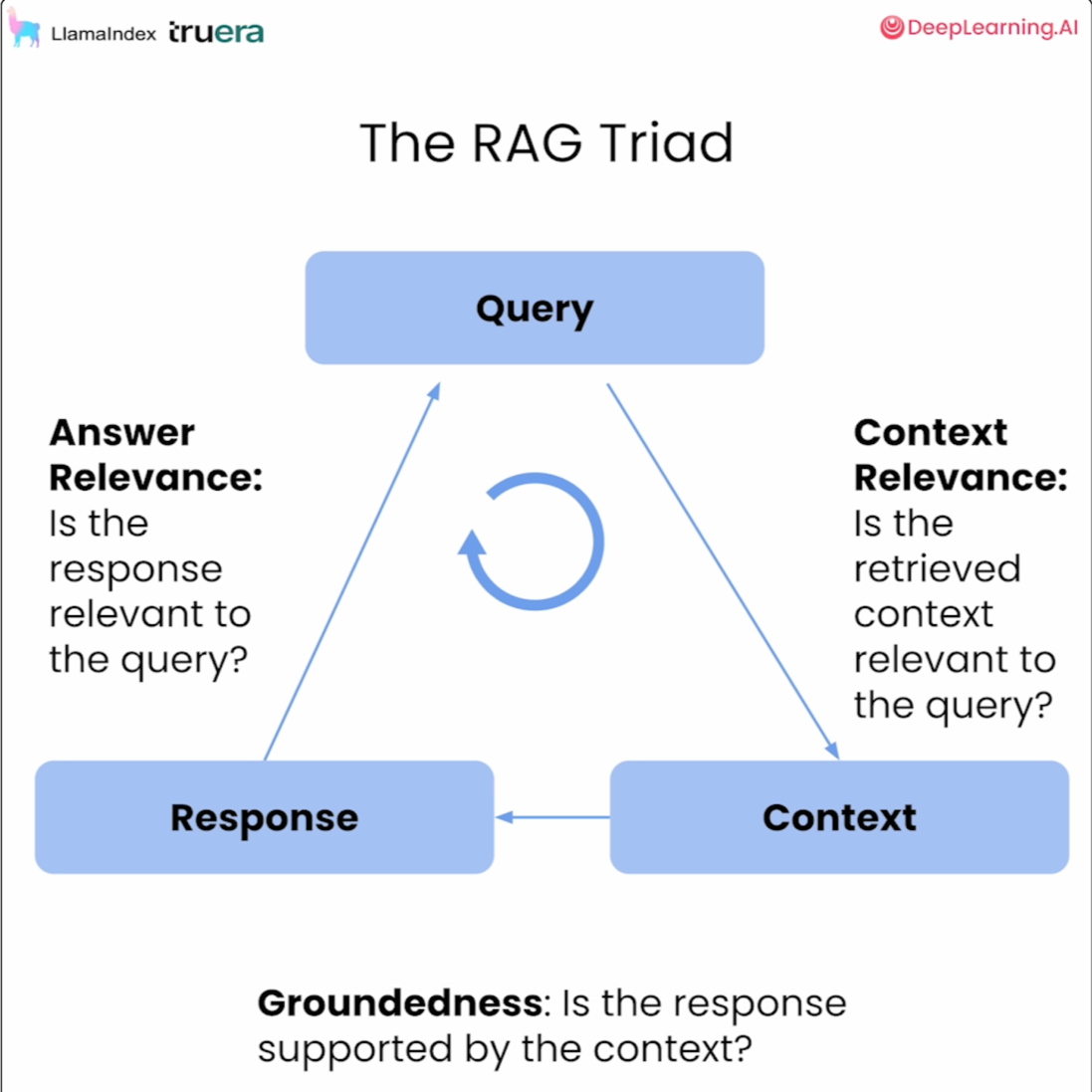
Alternatively, you can assess the different stages of RAG, using the “RAG Triad”: context relevance, groundedness, and answer relevance. These metrics are supported by the Truelens library, which is ideal for analyzing unstructured datasets.
- Context Relevance measures the quality of the information retrieval, ensuring that each piece of context is pertinent to the query. This step is crucial to prevent the LLMs from producing 'hallucinations' or irrelevant responses.
- Groundedness assesses whether the responses are well-supported by the retrieved context. To verify this, you can break down the response into individual claims and search for evidence within the context that substantiates each claim.
- Answer Relevance evaluates how closely a response matches the initial query, ensuring that the output is directly pertinent to the user's request.

Image caption: source
RAG related tools
To implement RAG, you don't need to start from scratch thanks to the amazing open-source community that offers comprehensive tools for each step of the process. Here’s a breakdown of the tools available:
-
- Embedding Extraction: For generating embeddings from text chunks, you have options like self-hosted servers or paid services (e.g., OpenAI, Cohere) and free, public hosted servers (e.g., Hugging Face).
- Storing and Indexing Embeddings: You can utilize vector libraries to store and index your embeddings effectively(e.g., Faiss, Elastic search, Annoy)
- End-to-End RAG Pipeline: Libraries such as LangChain and LamaIndex simplify the RAG process. They integrate various underlying tools to handle everything from building the index to prompting your chosen LLM effectively.
- Evaluating RAG Pipelines: It’s crucial to assess a RAG pipeline, especially in production settings. The RAG Triad—Answer Relevance, Context Relevance, and Groundedness—can be evaluated using the Truelens library, which helps ensure that your RAG system is performing optimally.
Resources: Deep dive into RAGs
For those looking to gain practical experience with RAGs, the DeepLearning.ai course, developed in collaboration with LlamaIndex and Truera, is an excellent resource.
Surveys are a fantastic way to quickly grasp the essential aspects of a topic. For instance, the survey titled "Retrieval-Augmented Generation for Large Language Models" by Gao et al., features an accessible Notion page that allows easy comparison and filtering of research papers based on specific benchmarks. Another notable survey is "Retrieval-Augmented Generation for AI-Generated Content" by Zhao et al., which provides insights into cutting-edge developments in the field.
At Pythonic, we're committed to leading the industry by not only staying current with technological advancements but actively integrating and refining them within our products. We go beyond standard implementation by continuously engaging with our customers, using their feedback to enhance our document understanding technologies.